

エッジAI時代に向けたDNN推論の高度化と高速化


古林 隆宏 Takahiro Kobayashi
SCSK株式会社
R&Dセンター AI技術部
2010年入社。以来、先進技術の調査研究と製品化支援を実施。モバイル開発向けBaaS基盤開発、ビッグデータ処理技術研究、深層学習による言語処理研究など時流にあわせた取り組みを実施。深層学習言語処理の成果はSCSKのテキストマイニング製品「VOiC Finder」のAI機能としてリリースした。近年では3次元データ処理・デジタルヒューマン等のXR関連技術開発を実施している。Scrum Alliance認定スクラムマスター/プロダクトオーナー。
エッジコンピューティングはネットワークの境界に近い場所にあるデバイス(エッジデバイス)を活用して、クラウドとエッジデバイスの間で処理やデータの共有を行い、高速で効率的な処理を実現する技術です。エッジコンピューティングはIoTやVRなどの分野で利用されており、エッジデバイスを活用したAI技術が注目を集めています。
当社はこれまでAIの深層学習手法として最も普及しているDNNによる機械学習手法をエッジデバイスで活用するため、DNNモデルの「高速化・軽量化」の研究を行ってまいりました。本稿ではその研究成果を「DNN高速化のための検討項目」として紹介しています。
DNN高速化のための検討項目
DNN(ディープニューラルネットワーク)処理の高度化や高速化の要求に対しては以下の3つの対処法があります。
(1)計算資源の増設(スケールアップ)
(2)処理の分散化(スケールアウト)
(3)処理や環境の最適化
しかし、スマートフォンやシングルボードコンピュータなどでDNNを動作させるエッジ用途において(1)や(2)は多くの場合現実的ではありません。また(3)には多くの手法が存在し、個々の手法の有効性はタスクや環境の性質により異なります。
本研究ではエッジ機器への適用を主眼に、(3)について全般的に検証し、各手法を適切に組み合わせて提案できる状態を実現することを狙いとし、その成果を「DNN高速化のための検討項目」としてまとめました。
1.はじめに
本研究は、近年のAIを構成する主要な要素であるDNNについて、その推論結果取得に要する時間を削減するために検討すべき項目をまとめました。
DNNの性能指標として第一に注目されるのはその精度ですが、その用途によっては推論速度(入力データを与えてから推論結果を得るまでの時間の短さ)がより重要な指標となることもあります。例えば自動運転AIにおいて「あと数秒で衝突する」という予測結果を得るために1分かかっていては、いくら精度が高くても意味がありません。
本記事では、DNN推論の高速化を次の3つの段階に分け、それぞれの段階において検討すべき選択肢をまとめています。
1. 処理基盤の高速化
2. DNNの軽量化
3. 軽量化による精度低下からの回復
処理基盤高速化には、主にハードウェアのスケールアップや、プログラムのDNN以外の部分の最適化が含まれます。DNN軽量化では、できるだけ性能を保ったままDNNの処理を簡略化して速度を引き出す手法を紹介します。最後に軽量化に伴い精度が低下することを想定し、精度向上のための手法を紹介します。
2. DNN推論高速化作業の流れ
まずDNN推論高速化の全体的な進め方について紹介します。 前提として、DNN推論結果の精度や、実利用時と同じ形で入出力を行った際の推論速度が計測できる状態であることを確認します。そうでない場合は、精度や速度の計測ができるようにまず環境を整える必要があります。
「実利用時と同じ形での入出力」を評価対象とするのは、DNN呼び出しのインターフェースを含めた、DNN処理の外側の部分に速度低下の要因が混入する場合があるためです。(詳しくは「3. 処理基盤の高速化」に記載。)
その上で、まずはDNNの処理基盤を最適化します。予算の範囲内で高速なハードウェアを準備し、ソフトウェアを精査して最適化可能なオーバヘッドを削減します。
その後、DNNの基本的な軽量化と、精度向上を試します。すなわち、DNNの構造を軽量なものに変更する、DNNのハイパーパラメータを調整して構造をスリム化するといった方法で軽量化を試み、また一般的な精度向上策でまだ試していないものがあれば効果を検証します。
それで十分でなければ、さらに踏み込んだ軽量化・精度向上(Pruningによる軽量化や、蒸留による精度向上)を適用することとなります。

3.処理基盤の高速化
DNN推論高速化のためにまず検討すべき事項として、処理基板の高速化、すなわちDNN推論に利用するハードウェアの高度化とDNNを呼び出すプログラムの最適化が挙げられます。
3-1. ハードウェアの高度化
ハードウェアのスケールアップは、最も話の早い高速化手法のひとつです。クラウド環境であれば、利用するインスタンスやGPUのグレードを上げるだけで高速化が期待できます。

オンプレミスのサーバやワークステーションであればGPUカードを上位のものに入れ替える、Jetsonなどのエッジ向け機器を使用している場合はそのグレードを上げるという選択肢があります。

画像出典: https://www.macnica.co.jp/business/semiconductor/articles/nvidia/133162/
大量のデータのバッチ処理や、頻繁に発生するインタラクティブな要求への応答については、スケールアウトにより高速化が達成できることがあります。
ハードウェアの視点では、GPUやサーバ自体を複数用意して並列分散処理を行うことになります。
また、DNN推論に特化した追加モジュール(いわゆるAIチップ)の利用も注目されています。 クラウド上では、GCP、AWS、AzureのそれぞれでAIチップが利用可能となっているほか、主にエッジコンピューティング向けに、USBドングルやシングルボードコンピュータに接続するモジュールの形で利用できる製品も複数登場しています。
AIチップを利用する上での注意点として、SDKやAPIがベンダー間で共通化されていないため、既存のモデルやプログラムを作り直す作業コストが発生することが多く、ベンダーロックインされやすいという点があります。そのため、AIチップベンダの事業継続性や、GPUなどの汎用環境との間の移植容易性について慎重に検討する必要があります。

3-2. ソフトウェアの最適化
DNN推論自体をどれだけ高速化しても、他の処理フローのどこかにボトルネックがあれば、最終的な応答時間短縮の効果は限定されてしまいます。そのため特にDNN推論を行うプログラムに的を絞り、確認すべきポイントを2点あげます。
入力データの準備
DNNに入力するデータの取得と前処理は、DNN推論を行うプログラムにおいてボトルネックとなりやすい箇所です。特に画像処理タスクは扱う入力データの量が多くなるため注意する必要があります。
基本構造として、高速化を目指す場合には入力データ準備処理とDNN推論処理はスレッドを分けるなどして並列実行するのが一般的です。DNN推論処理を待っている間に、次以降の入力データを準備しておく工夫などが考えられます。
またストリームデータを高頻度でリアルタイム処理したいという場合には、ストリームデータの取得処理自体が十分高頻度で動くような最適化が必要です。例えばWebカメラからの入力をリアルタイム処理する場合、Webカメラが15fps(=1秒間に15回の頻度で入力)で動作する設定になっていれば、DNN推論がどれだけ速くても15fps(=1秒間に15回の頻度で出力)以上の数値が出ることはありません。この場合はWebカメラの設定を変える、高性能なものに換えるなどして入力頻度自体を上げる必要があります。
DNNの呼び出し
DNNの呼び出し部分は、違う言語で作られたライブラリの呼び出しや、GPUなどの特殊デバイスの呼び出しなど、異質なものとのインターフェースが多く集まる部分であり、最適化すべきオーバヘッドが発生しやすい箇所です。
検証の際、特定の環境においてDNN呼び出しの方法を変えたところ、応答時間が40%短縮できたという事例もありました。
特に、初めて利用する環境において想定よりも速度が出ないという場合には、DNN呼び出し部分に最適化可能なオーバヘッドが潜んでいないか調査する必要があります。
4. DNNの軽量化
処理基盤に問題がなければ、次はDNNの軽量化手法を試していきます。DNNの軽量化は、基本的には精度の下落リスクと引き換えに計算量やメモリ消費量を削減していく手法なので、「5. 精度の回復」で紹介する精度向上策と組み合わせながら採用可否を見極めていきます。
4-1. 軽量構造の採用
DNNの設計思想は「精度重視で大規模化を厭わない」「精度は落とさずスリムに保つ」の2種類に大別されます。高速化を意識する場合は、スリム化を意識して設計された構造を採用するほうが有利です。そうでない構造のDNNを利用している場合には、構造を変更して学習と評価を行うと良いでしょう。
MobileNetV2は、2017年に提案され幅広い支持を得たモデルです。名前の通りモバイルやエッジ系の用途を意識し、軽量化しつつ精度も維持できるように設計されています。DNNを軽量化したいのであれば試す価値のあるモデルと言えます。
また、この後継となるMobileNetV3も2019年に提案されています。こちらはMobileNetV2に対して精度向上を目指しつつ、CPU実行時の高速化を目指したと述べられており、GPUで実行するとMobileNetV2よりも速度が劣るという声もあります。
ShuffleNetV2は、2018年に提案されたモデルであり、GPU上で実行した際の速度を重視した構造になっているのが特徴です。DNN軽量化の研究では軽量化の度合いをモデルのパラメータ数や積和計算回数で評価することが多いですが、ShuffleNetV2の研究ではこれらの指標が同じでも実行速度に大きな差が出る場合があることを指摘し、実際に計算した際の速度を重視した評価がなされています。
その他、新しいモデルが日々研究・提案されているので、要求にあった精度と速度のバランスをもつ構造を採用するとよいでしょう。
4-2. DNNの規模の調整
これはDNNのハイパーパラメータを変更してモデルを作り直すことにより、DNNの規模を調整する古典的な手法です。ただし、DNNの構造は複雑化しており、個々の層のサイズ等を直接手で調整することは現実的ではなくなってきています。
代わりに、同じ研究の中でDNNの規模にバリエーションをつけて構造が提案されることも多いため、提案されたバリエーションの中からより規模の小さいものに変更することでDNN規模の調整ができる場合があります。例えば、ResNetやDenseNetといったモデルには規模に応じた複数のバリエーションが提案されており、言語モデルBERTでもbaseサイズとlargeサイズの2種類が提案されています。
また、DNNの構造によっては、総合的に規模や複雑さを調整するハイパーパラメータが用意されている場合があります。上述のMobileNet系のモデルにはwidth multiplierおよびresolution multiplierというハイパーパラメータがあり、これらを大きくすれば複雑で高精度なモデルに、小さくすればスリムで高速なモデルに調整することができます。
また2019年に提案されたEfficientNetというモデルの研究は、基本となる最小の構造をまず定義し、その後1つの係数を調整することでDNNの層の数・各層の重みの数・入力画像の解像度がバランス良く変更できる方法を示しました。
4-3. Pruning(重みの間引き)
Structured Pruningの仕組み
Structured Pruningの特徴は、重みの構造を考慮し、サイズを特定方向に詰められるようにまとまった単位で間引きを行うことにあります。
単純なPruningでは、個別の重みをばらばらに間引いていくので、Pruningが完了しても計算の高速化に繋げるにはもうひと工夫が必要でした。Structured Pruningでは、例えば重み行列を列ごと間引く場合、その分横方向のサイズを詰めることができるといったように、重み行列を特定方向に詰めることで明確に計算の規模が小さくなります。

2020年1月時点では、畳み込み層のチャンネルもしくはフィルタ単位でのStructured Pruningがよく用いられているようです。
畳み込み層の重みは、イメージとしては3次元の行列が複数並んでいるような構造になっています。行列の1・2次元目は画像の縦横に対応し、3次元目がチャンネル、個別の行列それぞれはフィルタと呼ばれます。
チャンネルをまとめて間引く手法はチャンネルPruning、フィルタをまとめて間引く手法はフィルタPruningと呼ばれます。

ここで、DNNにおけるチャンネルとフィルタの働きについて説明します。チャンネルのイメージがつきやすい例として、グレースケール画像とカラー画像の差が挙げられます。グレースケール画像は明暗のみの1チャンネル、RGBのカラー画像は赤・緑・青それぞれの情報をもつ3つのチャンネルから構成されます。このように、チャンネルを複数持つことで、同じ画像に対して様々な観点の情報を保持できるようになります。
DNNの中間値においては、チャンネル数は64や128などに増えることが普通であり、その各チャンネルは色の成分といった直感的に理解可能な特徴ではなく、DNNにとって都合のよい複雑で細分化された特徴を保持していると理解されています。
一方フィルタ数は畳み込み層から出力したいチャンネル数により決定されます。入力8チャンネル、出力16チャンネルの畳み込み層では、8チャンネルの入力に対して16個の異なるフィルタをそれぞれ適用し、その16通りの結果を束ねたものが16チャンネルの画像として出力されます。

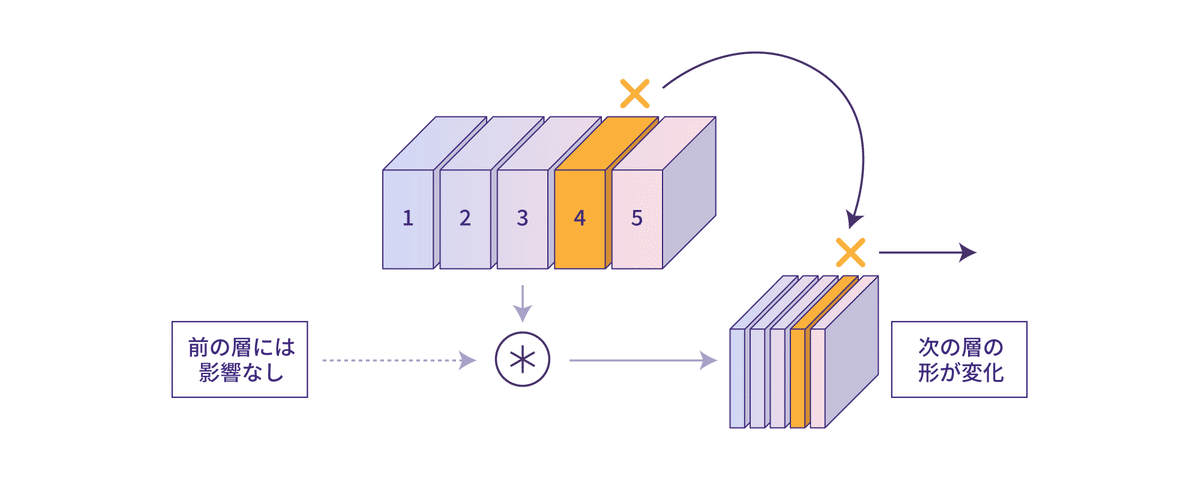
チャンネルPruningとフィルタPruningの違いは、主に行列を詰める際の後処理に現れます。行列を詰める処理を行うと入出力の形が変わるため、Pruningの対象となる層に隣接した層も重みを行列の形が変わります。
畳み込み層の重みのチャンネル数は入力画像のチャンネル数に対応するため、チャンネルPruningを行った層の前の層が影響を受けます。一方畳み込み層のフィルタ数は出力画像のチャンネル数に対応するため、フィルタPruningを行った層の後の層が影響を受けます。
チャンネルPruningとフィルタPruningは、効果の上では顕著な差はありませんが、圧縮の影響を及ぼす方向が違うという点がStructured Pruningの対象とする層の選定に影響を及ぼすことがあります。
Structured Pruningの実装
DNNの実装にPyTorchを用いている場合は、DistillerというOSS製品がStructured Pruningの実装を提供しており、さらに間引いた不要な重みを圧縮し高速化を実現する機能(DistillerではNetwork Thinningと呼ばれる)も提供されているため、Distillerによる実装を基本とするのが良さそうです。
このNetwork Thinningに相当する機能がないと肝心の高速化が達成できないため、Distiller以外の実装を利用する場合にもこの点注意が必要があります。
一方DNNの実装にTensorFlowを用いている場合は、2020年1月時点ではOSSとして利用可能なStructured Pruningの実装としてこれというものがなく、自前で実装することになりそうです。
ハイパーパラメータ調整
Structured Pruningを実行する場合には、ハイパーパラメータとして以下を設定することになります。
Pruningの対象とする層はどれか
どの程度まで間引くか(0%-100%)
チャンネルPruningとフィルタPruningのどちらを行うか
Pruningの開始時期・終了時期(エポック数)
Pruningの対象は、まずはすべての畳み込み層としてよいと考えます。 間引きの割合については、50%や70%といったところから始めて、精度と速度の兼ね合いから調整していくことになります。チャンネルPruningとフィルタPruningは、基本的にはどちらを選んでもあまり差はないと考えます。
Pruningを開始するのは、モデルがほぼ学習を終えた後がよいでしょう。学習済みモデルに対してPruningを適用する場合には、0エポック目から開始します。終了時期については、早すぎず遅すぎずといった範囲で調整する必要があります。
4-4. DNN軽量化 物体検出モデルへのPruning応用検証
本研究ではStructured Pruningについて、より応用的な物体検出モデルにおける効果を検証しました。対象タスクは魚移送用水路を流されていく魚の認識とし、下記2つの評価方法により確認しました。
■速度改善の評価
エッジデバイス(Jetson nano)においてPruning前後での画像処理FPS値を比較します。
■精度への影響の評価
Pruning前後での物体の検出精度について、複数の画像サンプルに対する出力を題材に定性評価を行います。
Pruningのレシピ
■SSDの高速軽量なバリエーション

(1)のMobileNetV2部分でPrune可能な層の70%にPruning(間引き)を行います。結果的に、パラメータ数は約300万から約153万まで削減でき、モデルファイルサイズは12MBから6MBまで減少しました。
速度改善の評価
100フレームごとのFPS値を算出したところ、5.54 から5.89と、Pruningにより6.4%性能向上が見られました。
精度への影響
■検証データに対する損失値
損失値(小さいほどよい)はPruningにより2.48から2.42に変化しました。精度の観点から言えばほぼ同等(わずかに改善しているが誤差の範囲)と言えます。
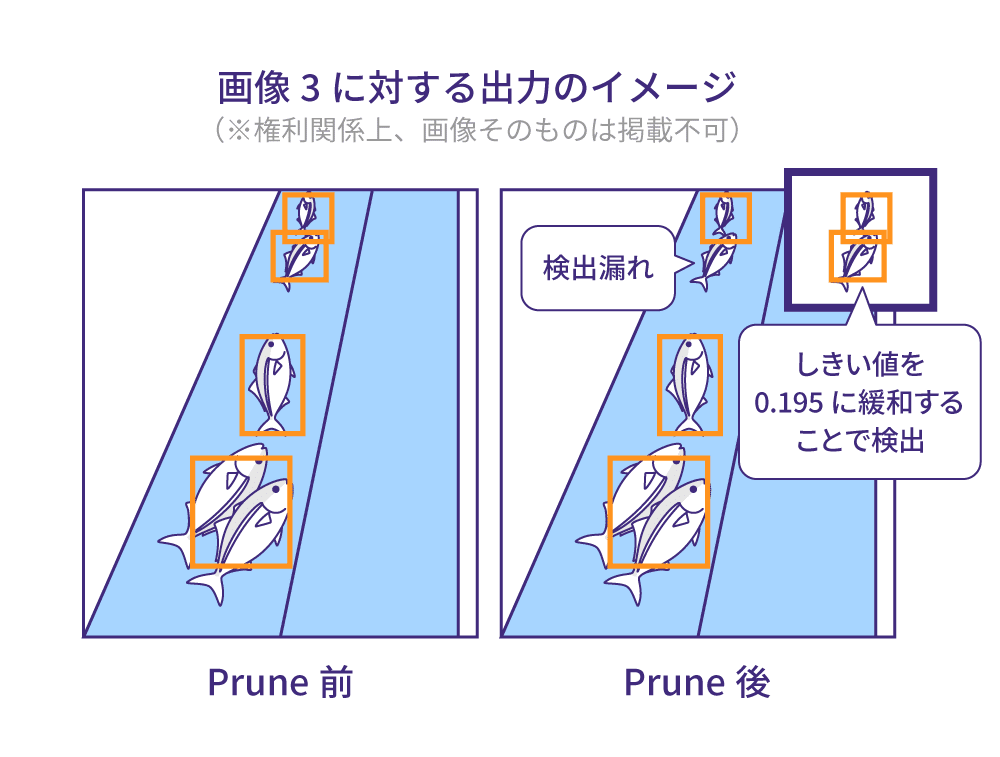
■サンプル画像に対する出力の定性評価
評価用データセットから画像を4枚ピックアップし、バウンディングボックスと魚の位置と個数の対応を確認しました。推論時パラメータは、スコア0.2以下のバウンディングボックスは無視し、IoU0.5以上の重なりをもつバウンディングボックスの集団については一番スコアの高いもののみを採用(Non-Maximum Suppression)しました。
精度への影響の評価
基本的には、Prune前とほとんど同等の出力が得られましたが、4枚のうち、画像3において1件検出漏れが発生しました。認識はされていましたが、スコアが変化し、しきい値の0.2をわずかに下回ったのが検出漏れの原因でした。
総括
検証の結果Structured Pruningが物体検出モデルにも適用可能であることが確認できました。また実際に推論速度の向上や、物体検出の精度への影響はValidation Lossが同等、サンプルによる定性評価はほぼ同等ですがスコアに影響があることを確認しました。
5. 精度の回復
基本的に、DNNを軽量化すると精度は下がります。ここでは、その課題に対する精度向上策について紹介します。
5-1. 一般的な精度向上策
比較的低い作業コストで導入可能な精度向上策を紹介します。
データ増幅
入力データをランダムに加工することで、DNNが訓練時に様々な入力データを経験できるようにします。
主に画像処理に用いられる手法で、画像の拡縮、切り抜き、回転、反転(上下/左右)、シアー(斜め変形)、色の加工(色相/彩度/明度)、ノイズの付加など様々な加工方法があります。
認識対象が文字の場合は左右反転しないなど、加工の種類や強さは対象となるデータに合わせて調整する必要があります。
Mixup
訓練時に2枚の入力画像をランダムな割合で混合し、正解ラベルとしてもぞれぞれのクラスを混合したものを与える手法です。
人間の感覚では理解しかねる見た目でありますが、DNNに解かせる問題をより複雑にすることで精度を上げると考えれば、上述のデータ増幅の延長線上にあるものとして捉えることができます。
またMixupには様々なバリエーションが研究されており、入力ではなくDNNの中間データを混合するManifold Mixup、画素全体を重ねるのでなく一方の画像の一部領域を切り取って他方の画像で埋めるCutMixなど、様々な手法が提案されています。

重み減衰(weight decay)による正則化
損失値の計算にDNNの重みのL2ノルムを含めることで、重みの絶対値が大きくなりすぎることを防ぎます。これは過学習を防いで実用上の精度を上げる効果があるとされています。
Dropout
DNNの層の間の接続のうち一定割合を訓練時のみランダムに切断する手法で、過学習を防ぐ効果があるとされています。
古くから常套手段的に用いられている非常に強力なテクニックですが、他の精度向上策が発展してきた結果、近年ではDropoutがないほうが高精度な結果が出るケースも報告されています。切断する割合を下げたり、ゼロにしたものと一度比較してみるのも良いでしょう。
5-2. 蒸留による精度の向上
機械学習において蒸留(Knowledge Distillation)とは、訓練対象のモデルの他にお手本となる学習済みモデルを用意し、同じ入力に対する出力を比較することで正則化を行う手法です。 DNN推論高速化の観点では、大規模で精度の高いモデルをお手本として、スリムで高速なモデルの精度を高める使い方をします。
蒸留の実装
ある入力に対する訓練対象のモデルの出力をy1、同じ入力に対するお手本学習済みモデルの出力をy2とすると、y1とy2の誤差を正則化項として損失値に追加すれば蒸留は成立します。 この項を蒸留誤差と呼びます。蒸留の誤差算出にはクロスエントロピーがよく使われますが、L1距離やKLダイバージェンスなどが使われる場合もあるようです。
また、モデルの出力は通常Softmax関数で正規化を行いますが、蒸留誤差を求める際には、Softmax関数を適用する前にy1およびy2をハイパーパラメータであるtで割ります。tは温度と呼ばれ、おおむね1.0から4.0程度の値が用いられます。訓練対象のモデルの表現力に余裕がある場合には温度tを高めに設定するとよいとされています。
上記を擬似コードにまとめると、蒸留を行う場合の損失値は以下のように表現できます。

ただし、yは正解ラベルとし、crossentropyは2つの引数のクロスエントロピーを算出する関数とします。第1項は通常の誤差項、第2項が蒸留誤差の項です。重み減衰などのその他の正則化テクニックを用いる場合には正則化項を順次加算していきます。
さらに、通常の誤差値と蒸留誤差のバランスを、ハイパーパラメータαで調整することがよく行われます。αを反映すると擬似コードは以下のようになります。

0 < alpha ≦ 1 であり、一般的には0.9や0.95などの1に近い値にするのが有効と言われています。 また実装上の注意点として、お手本の学習済みモデル自体は重みを固定して中身が変化しないようにする必要があります。蒸留は訓練対象のモデルをお手本モデルに近づけることが目的なので、お手本モデルのほうが訓練対象のモデルに近づいてしまっては意味がないからです。
y2の算出のみ学習モードでなく推論モードで行う、勾配の伝播を停止する構文を使用するなど、利用する機械学習フレームワークにあわせて対策が必要になります。
蒸留の効果
蒸留の効果について、SCSKでの検証において以下のことが確認されました。
■検証精度が向上する(訓練精度はあまり向上しない)
蒸留により主に検証精度、すなわち訓練データに含まれないデータに対する精度が向上しました。対照的に、訓練データに対する精度はあまり向上が見られませんでした。学習の効果は訓練データに含まれないデータをもとに評価すべきというのは機械学習一般に言えることではありますが、蒸留では特にその重要性が高いと言えそうです。
■場合によっては、訓練対象モデルの精度がお手本モデルを上回る
訓練対象モデルの精度がお手本モデルを上回るケースがあることが確認されました。これにより、蒸留というプロセスは、訓練対象モデルにお手本モデルのマネをさせるというよりは、蒸留誤差という新しい情報を学習に導入することで訓練対象モデルにより豊富な経験を積ませるように働くものであると考えられます。
■訓練対象モデルの表現力が低い場合、あまり効果がない
訓練対象モデルの種類が変われば、蒸留による性能の向上幅も変わることが確認されました。たとえばAlexNet、MobileNetV2、ResNet18で比較すると、AlexNetにはあまり効果がなく、MobileNetV2は中程度、ResNet18はこの中では最も精度向上幅が大きいという結果を得ました。 さらに、前述のPruningにより軽量化を行ったDNNの蒸留は、軽量化しない場合よりも精度向上が少ないという結果を得ました。
6. その他の高度なDNN軽量化技術
ここでは、現在研究されているDNN軽量化技術のうち、現状では実装や高速化達成のハードルが高く、実案件への投入にはさらなる成熟が必要と思われるものを紹介します。
6-1. Neural Architecture Search(NAS)による規模最適化
Neural Architecture Search(以降は、“ニューラルアーキテクチャ探索”と表記)は、DNN規模の調整そのものをディープラーニングによって実施する技術です。現状ではDNN規模の調整は、何らかの経験則により手で実行するか、グリッドサーチやベイズ最適化などのアルゴリズムによって行っていますが、これを学習の中で自動で達成するのがニューラルアーキテクチャ探索の目的です。
現在のニューラルアーキテクチャ探索の主流は、Controllerと呼ばれる規模の調整を行うモデルを置き、最終的に解きたいタスクを処理するモデル(Child Networkと呼ばれる)を繰り返し作成することで、その性能を評価しながらChild Networkの規模を調整していくというスタイルになっています。 Controllerの訓練には強化学習の手法を用います。
ニューラルアーキテクチャ探索を用いるメリットとしては、人間が試行錯誤を行う手間を省いたうえで、要件に応じてDNNを最適に近い規模に調整できるということがあります。
一方ニューラルアーキテクチャ探索の課題は、必要とする計算量の多さにあります。イメージとしては、今まで人間が試行錯誤で規模調整を行っていたのをControllerが肩代わりするような形であるので、色よい結果が出るまでChild Networkを繰り返し訓練するというスキームであることには変わりなく、何度も試行すればその分計算量が増大していくことになります。
ニューラルアーキテクチャ探索に必要な計算量を削減する研究は盛んに行われており、Child Networkを作り直す際に1世代前のChild Networkの重みを流用するENASという手法が有名なほか、前述のEfficientNetの研究において「基本となる最小の構造」はニューラルアーキテクチャ探索で生成しているため、これをニューラルアーキテクチャ探索と経験則を組み合わせて計算量を削減する手法と捉えることもできます。
今後ニューラルアーキテクチャ探索技術が発展していけば、特に実務上の利用においては、DNNのハイパーパラメータチューニングはニューラルアーキテクチャ探索に任せ、人間はもっと別の課題に注力するといった状況になっていくことが期待できます。
6-2. 量子化による軽量化
量子化という語には分野により様々な意味がありますが、DNN量子化とは、DNNの内部で計算に用いる値のビット数を落として計算時間やメモリ消費の削減を目指すことを指します。
具体的には、DNN内部の計算には一般的に32ビットの浮動小数点数が用いられますが、これ を16ビット浮動小数点数や8ビットの整数に置き換えます。より極端な手法では1ビットのバイナリ値にまで圧縮することもあります。
何も考えずにビット数を落とすと精度が下がってしまうので、「量子化の際に値を変換する方法を工夫する」「DNNの構造を工夫する」「量子化後の値を考慮しながら学習を行う」などの対策が研究されています。
精度の低下も課題ですが、現時点での実課題への適用という観点からはDNN量子化の最大の課題は「高速化の難しさ」にあります。
例えば、GPUは浮動小数点数の計算に特化しているので、整数値の計算をさせようとするとかえって遅くなることがあります。CPUにおいても同様の問題は存在し、SCSKでの検証において8ビット整数に量子化したDNNによる推論が、ARMのCPUでは量子化前よりも高速に計算できますがIntelのCPUではかえって時間がかかるといったケースが確認されました。
また、DNNを動かすソフトウェアやミドルウェアについても、16ビット浮動小数点数や8ビットの整数の計算については32ビット浮動小数点数の計算ほど最適化が行き届いていないために高速にならない場合があります。
まとめると、DNN量子化による高速化を達成するには、量子化後のデータ型にソフトウェアとハードウェアの両方がきちんと対応できていることが必要となります。
この点では、ソフトウェアとハードウェアがセットで提供されるAIチップは量子化が利用しやすい環境と言えます。例えばGoogle陣営によるAIチップであるCoral TPUでは、ハードウェア自体が量子化されたDNNを前提に設計され、付属のツールでCoral TPU向けにモデルを変換すると自動的に量子化が適用されるようになっています。
このような状況を鑑みるに、DNN量子化はモデルの作成者が意識して適用可否を判断する技術というよりは、DNN計算の実行環境内部に組み込まれ、暗黙のうちに高速化に寄与するような使い方になっていきそうです。
7. おわりに
本研究では、処理の速さがカギとなるビジネス課題へのAIの適用を念頭に、DNN推論の高速化にあたり考慮すべきポイントを調査しました。 まずは一般的なソフトウェア開発と同様の観点からハードウェアとソフトウェアの高速化を試み、その後DNNの軽量化を試すというのが大きな流れです。
また、DNNの軽量化策は精度劣化を伴うことがあるため、必要に応じて精度回復に工数や計算資源を割くことも時に必要になります。
軽量化や推論精度向上などのDNNに関する工夫については、新しい手法が次々に提案されていくので、ある時点で広く信頼されている手法であってもその評価は少しずつ変化していきます。定番とされる手法にも入れ替わりがないかなど、大きな動きについては定期的に状況を確認していくことが重要と言えます。
本研究に関連する最新の研究はこちら
FPGA を活用した量子 AI シミュレーターの研究開発で従来比 1,000 万倍の高速化を実現