

プログラムから説明文章を生成するAI~ CodeBERT~


瀬在 恭介 Kyousuke Sezai
SCSK株式会社
R&Dセンター 技術開発部
2016年、SCSK株式会社に入社。金融業界にてシステム開発全般の業務に従事。 2019年から研究開発部門にてAI研究チームリーダーを務め、自然言語処理AIや知識グラフに関する技術開発、論文寄稿、知財取得、事業支援に従事。
この記事では自然言語処理の応用例として、プログラミング言語を学習した「CodeBERT」というモデルを用い、プログラムコードから説明文章を生成するAIについて紹介します。
CodeBERTとは
自然言語処理の分野では、2018年に登場した自然言語処理モデル「BERT」が様々な場所で使用され、より発展的な研究も行われるようになりました。
中でも注目されているのが「マルチモーダル学習」という手法です。
この学習手法では、「画像」「テキスト」「音声」「動画」といった複数の形式の異なる情報を学習データとして使用します。これにより大量の情報を得ることで、性能向上や用途の拡充を目指します。今回の「CodeBERT」はBERTで使用される一般的なテキストに加え、プログラミング言語も同時に学習させたモデルであり、プログラミング言語と自然言語両方の意味を理解するモデルと言えます。
また、マルチモーダルに関連して、1つの形式の学習データを使用することを「ユニモーダル」、2つの異なる形式のデータを使用することを「バイモーダル」と呼びます。

論文: CodeBERT: A Pre-Trained Model for Programming and Natural Languages
学習データは上記の様なプログラムコードに加えて、赤枠内のプログラムコードを説明したコメントも学習させています。
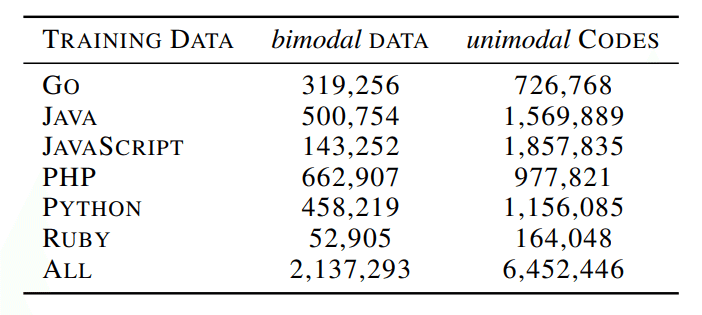
論文: CodeBERT: A Pre-Trained Model for Programming and Natural Languages
CodeBERT は、Go、Java、JavaScript、PHP、Python、Rubyの6つのプログラミング言語について、合計約210万のバイモーダルデータと約640万のユニモーダルデータを使用して学習しています。
学習済みCodeBERTの使用
学習済みBERTを簡単に使用する方法として「transformers」というライブラリを使用する方法があります。 今回のCodeBERTは、Microsoftで学習されたモデルが「transformers」で提供されており、これを利用してCodeBERTを呼び出していきます。
▼transformersを使用した学習済みCodeBERTの呼び出し
import torch
from transformers import RobertaTokenizer, RobertaConfig, RobertaModel
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
tokenizer = RobertaTokenizer.from_pretrained("microsoft/codebert-base-mlm")
model = RobertaModel.from_pretrained("microsoft/codebert-base-mlm")また、CodeBERTは学習タスクとして、プログラムの穴埋め問題を行っているため、プログラムの一部を穴埋め状態にし、正しい予測が可能か検証してみます。
▼「if (x is not None) mask」のmaskを予想するタスク
from transformers import RobertaConfig, RobertaTokenizer, RobertaForMaskedLM, pipeline
model = RobertaForMaskedLM.from_pretrained("microsoft/codebert-base-mlm")
tokenizer = RobertaTokenizer.from_pretrained("microsoft/codebert-base-mlm")
CODE = "if (x is not None) < mask > (x>1)"
fill_mask = pipeline('fill-mask', model=model, tokenizer=tokenizer)
outputs = fill_mask(CODE)
print(outputs)回答は以下が出力されました。(左から上位5個出力)
'and', 'or', 'if', 'then', 'AND'正しく、if文で使用されそうな単語が選ばれています。
CodeBERTを使用した説明文章生成タスクの実施
プログラムから文章を生成するタスクを実施していきます。
説明文章生成タスクを実施する為のサンプルコードは以下で提供されています。
https://github.com/microsoft/CodeBERT
内容は、GitHubに上がっているプログラムコードのURLとその説明文章(英語)がデータとして保管されており、以下のように様々な言語データが用意されています。
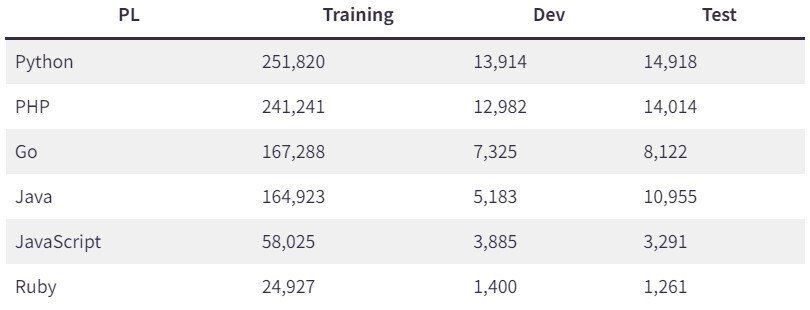
今回はCodeBERTの後続に文章生成を得意とする「Seq2seq」モデルを結合させ、プログラムコードをインプットに説明文章をアウトプットするモデルを使用しました。
学習済みモデルを使用し、実際にテストデータで生成した文章が以下になります。
▼生成文章と正解文章の比較
正解:Downloads Dailymotion videos by URL .
予測:Download a file from a URL 最後に
CodeBERTの生成文章は短くまだ実用段階には至っていませんが、プログラムコードから説明文章を生成できました。将来的にはエンジニアリングをサポートし、システム開発に貢献するモデルが開発されるようになると予想します。
また、自然言語処理分野で名を馳せたBERTは、プログラミングだけでなく、動画や音声といった様々な分野への応用研究が進められています。
自然言語処理AIはビジネスの現場での活用がまだ限られていますが、近い将来当たり前のように役立つ時代が来ると期待されます。