

汎用言語分散表現モデル「BERT」を使用した要約モデルの研究 ~自然言語解析の高度化~


瀬在 恭介 Kyousuke Sezai
SCSK株式会社
R&Dセンター AI技術部
2016年、SCSK株式会社に入社。金融業界にてシステム開発全般の業務に従事。 2019年から研究開発部門にてAI研究チームリーダーを務め、自然言語処理AIや知識グラフに関する技術開発、論文寄稿、知財取得、事業支援に従事。
AIによる自然言語処理は、大規模テキストデータの解析や機械翻訳、音声対話システムなどに使用され、マーケティングやビジネスシーンのほか、日常生活の利便性を高めるあらゆる分野で活用されています。 当社はこれまで自然言語処理AIの処理精度向上と高速化を目的として、汎用言語分散表現モデル「BERT」を研究してまいりました。本稿ではその研究成果を紹介いたします。
BERT研究の目的
2018年にGoogleから発表された自然言語処理の言語モデルであるBERTは、ファインチューニング(※1)を行うことにより多数の自然言語処理タスクで高い性能を実現したことで注目を浴びました。BERTを使用することで、以下の項目が実現可能となります。
① 自然言語処理タスクに汎用的に使用できる分散表現を取得可能
② 少量データで、BERT以前の言語モデルと同様の精度取得が可能
③ 単語の文脈まで含めた分散表現を取得可能
本研究では上記項目について下記の通り調査・検証を実施します。
文章分類タスクを用いて①②の機能検証を実施し、自然言語処理タスクの基盤としての有効性を調査する
③を用いて文章要約モデルを作成し文章の要約・校閲タスクの負荷軽減につなげる
※1 ファインチューニング: 追加学習の手法の一つ。学習済みモデルに新たな層を追加しモデル全体を再学習させる手法。
BERT研究の背景
自然言語処理の課題
近年ニューラルネットワークを活用した機械翻訳の精度向上により、自然言語処理はビジネス利用が可能な段階に近づいています。AI市場の中でも自然言語処理は最も大きい領域を占め拡大を続けていますが、現状様々な課題が残されています。
【自然言語処理の課題】
タスク毎に文字を特徴化するモデルを作成する必要がある
照応省略解析(こそあど言葉)など省略された語句を読み取れない
大量のデータが必要
文と文とのつながりを理解出来ない
語句に隠された暗黙な意味を理解出来ない
BERTの登場
BERTは様々なタスクに利用可能という汎用的な言語表現取得モデルであり、文と文の繋がりを理解し少ないデータで学習が可能という特徴を持ちます。 2018年、自然言語処理の多くのタスクで SOTA (※2)を大きく更新しました。
参照:「BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding」https://arxiv.org/pdf/1810.04805.pdf
※2 SOTA(State-of-the-Art): 「最先端の(技術)」という意味をあらわす慣用句。機械学習においてはある特定の機械学習モデルやタスクが「現時点での最高のスコア・精度」を達成していることを表します。

BERTを使用すると自然言語処理の課題とされている下記の1~5の項目の内、1~4の課題が解決されるとされています。
タスク毎に文字を特徴化するモデルを作成する必要がある
照応省略解析(こそあど言葉)など省略された語句を読み取れない
大量のデータが必要
文と文とのつながりを理解出来ない
語句に隠された暗黙な意味を理解出来ない
BERTモデル
Attention
BERTモデルは、Attention技術を組み込んだTransformerのエンコーダーで作成され、文章を入力し単語ごとの分散表現や文章全体の分散表現を出力できます。

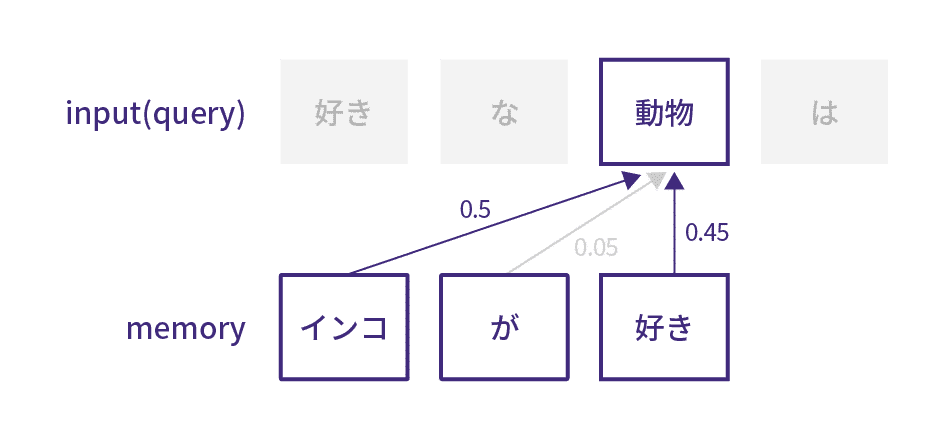
Attentionは文章の各単語に文脈情報を付加する機構です。例えば「動物」という単語に一番紐付きが高い単語情報を付加し、同じ文章でAttentionを実行すると、文脈情報が取得可能になります。 Attentionは、文章内の離れた位置にある単語情報も取り入れることによって、文脈を深く考慮する人間の感覚に近い処理が可能です。
Transformer
TransformerはAttentionのみを使用した言語生成モデルであり、エンコーダーとデコーダーで単語位置情報を付加し、Attentionを実施した入力データと教師データで再度Attentionを実施した特徴を元に文章を生成します。
BERTの事前学習方法
BERT は24層の巨大モデル(約110M)で大量の言語情報データを事前学習した言語モデルです。事前学習での入力と出力は、文章を入力値としコンピュータが単語の意味を理解しやすくするため、各単語の分散表現(ベクトル表現)を出力します。

BERTの事前学習タスクにはMasked Language Modeling(穴埋めタスク)と、Next Sentence Prediction(隣接文予測タスク)の2種類が採用されています。
Masked Language Modeling (穴埋めタスク)
入力文の15%をランダムに[MASK]トークンに置き換え、[MASK]以外の単語から[MASK]の元の単語を予測するタスク。当タスクにより文脈情報も加味した単語意味表現を学習します。

Next Sentence Prediction (隣接文タスク)
2つの入力文に対して「その2文が隣り合っているか」を当てるタスク。当タスクにより文章単位での意味表現を学習します。
![[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] ⇒ isNext 男は[MASK]店に行った。彼は1ガロン[MASK]の牛乳を購入した。
[CLS] the man [MASK] to the store [SEP] penguin [MASK] are fight ##less birds [SEP] ⇒ notNext
男は店に[MASK]。ペンギン[MASK]は飛べない鳥である。](https://assets.st-note.com/img/1715842889784-TBADJfHHnU.jpg?width=1200)
BERTの特長
文脈の理解
BERT以前の言語モデルであり2層のニューラルネットワークで大規模データによる分散表現学習を行う「Word2Vec」は、「単語」単体を理解することしかできませんでしたが、BERTは文章の「文脈」を理解することが可能です。
例)Word2Vec: 電気を消して。やっぱり電気を消すことをやめて。 BERT: 電気を消して。やっぱりそれをやめて。

BERTを元に開発された、代表3言語モデル
2019年までにBERTは2,000件近くの論文に被引用され、BERTをベースとした様々なモデルも登場しました。ここではBERTを元に開発された、代表3モデルの調査結果を紹介します。
XLNet
XLNetはBERTの事前学習方法を改良したモデルです。タスクの結果だけ見るとBERTの上位互換の性能となっています。XLNetはSQuAD(※3)(質問応答)、GLUE(※4)(感情分類や固有表現抽出など9タスク)など20のタスク全てでBERTを超え、うち18のタスクでSOTAを更新し、結果としてBERTの全タスクを更新するほどの性能を発揮しました。
SQuAD(質問応答)

RoBERTa
RoBERTaはBERTの事前学習方法(主にパラメーターチューニング)を改良したモデルです。学習データを追加しているので、データ量を増やさなくても BERT より良い結果となりました。さらにデータを増やしてより長く学習することでBERTの性能を最大限まで発揮し、 XLNet を上回る結果も出ています。
SQuAD、GLUE(感情分類と2文の含意関係)

ALBERT
ALBERT はBERTのパラメーターを改良して軽量化&性能向上を実現した言語モデルです。最も構造が巨大なALBERTのモデルでさえ、BERT-large以下のサイズに収まりつつ、性能はBERTを超えています。加えてALBERTは構造を大きくすることで性能の向上が可能です。ALBERTはパラメーター数を減少させつつBERTを超える性能を実現しています。
SQuAD(質問応答)
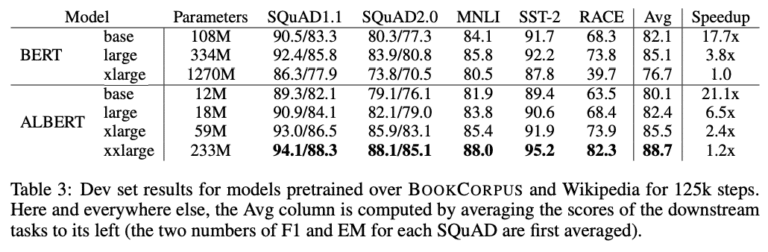
各手法の比較
各手法の内容を下記の表にまとめました。※下線はBERTと差異があるもの

GLUE (読解)

SQuAD 2.0 (機械読解) ※EM:回答抽出タスク/F1:文章分類タスク

このようにBERTを改良することでSOTAが大幅に更新されることが分かります。 BERTの補正モデルは引き続き更なる性能向上が図られ、言語モデル研究は進んでいくものと考えられます。また今後は自然言語を利用したタスク(読解/含意/換言/対話/要約/翻訳)全般に適用可能なモデル開発に注目が集まることが予想されます。
※3 SQuAD(Stanford Question Answering Dataset): wikipedia の記事に対してクラウドワークの協力者が作成した質問と回答の組み合わせデータベース。
※4 GLUE(The General Language Understanding Evaluation): 自然言語処理タスクにおける一般言語の理解度を評価するためのベンチマーク。9つのタスクで構成されます。
BERTを用いたSCSKの研究
1.文章分類
簡素な分類モデルを使用して、Livedoorニュースコーパスの7,376記事と2,000記事での9クラス分類を実施しました。その結果、BERTの方が精度が高く半分以下の文章に対しても精度低下しにくいことを確認しました。

2.文章要約
以下3つの文章抽出要約モデルに対しBERTとDoc2Vecで学習した結果を比較しました。
LexRank を使用した要約(Livedoorニュースコーパス)
双方向LSTMをベースとした要約モデル を使用した要約(Livedoorニュースコーパス)
単方向RNNをベースとした要約モデル を使用した要約(コールセンター)
LexRank要約モデルと双方向LSTMをベースとした要約モデルを使用した要約結果の比較
LexRank要約モデルは「多くの文に類似する文は、重要文であり、重要な文に類似する文は,重要文である」という定義のもと、文章を優先付けするアルゴリズムです。 LexRankは、Webページの重要度をはかるPageRankに着想を得たアルゴリズムであり、文間の類似度を用いてそれぞれの文の重要度を算出しグラフを構築することによって文をランク付けします。要約文はランキング上位の文を組み合わせることによって形成されます。

双方向LSTMをベースとした要約モデルは、各文章と正解要約文とのROUGEスコア(※5)を学習させるモデルです。双方向LSTMとは、文章の前から学習して次の単語の意味を予測する通常のLSTMに対し、ある文章の前後の文章も学習することで文脈から単語の意味を予測させるニューラルネットワークの手法の一つであり、RNN(再起型ニューラルネットワーク)の拡張バージョンです。
それぞれのモデルで、10文章の平均を抽出結果と正解要約文のROUGEスコア(要約評価指標)で評価した結果、両モデルでBERTの優位性を確認しました。
LexRankのROUGEスコア比較

双方向LSTMをベースとした要約モデルのROUGEスコア比較

※5 ROUGE(ルージュ): 一般的なテキスト要約の評価指標。大まかには人間の作成した要約とシステムが作成した要約との一致度を測るものです。
■自作要約モデルを使用した要約
自作要約モデルのROUGE学習推移

双方向LSTMをベースとした要約モデルは改良によるRougeスコア向上の可能性があります。
■LexRankの要約結果
正解要約文

BERT抽出文 ROUGEスコア:0.875342

Doc2Vec抽出文 ROUGEスコア:0.725

原文

単方向RNNをベースとした要約モデルを使用した要約結果の比較
単方向RNNをベースとした要約モデルは、各文章に1(要約文)0(非要約文)の教師データを学習させるモデルです。単方向RNNとは、ネットワーク内部に再帰構造を持つという特徴を持つニューラルネットワーク手法で、入力層、中間層、出力層の3つの層からなり、そしてこのネットワーク構造を時間や状態軸方向に展開することで、文章や時系列データの次の状態が予測できます。
以下は、単方向RNNをベースとした要約モデルを使用した抽出結果を目視で確認し評価したものになります。
acc1:要約文の分類精度 acc0:非要約文の分類精度

結果は、lossはBERTの方が低く、平均精度については僅かですがBERTの方が高い結果となりました。
■単方向RNNをベースとした要約モデル抽出結果比較
BERTの方が重要度値も高く、内容も決定事項が記載されており、より良い要約となりました。
BERT抽出文

Word2Vec抽出文

まとめ
BERTには自然言語処理タスクの精度向上や少量データでの学習、様々なタスクに利用可能という汎用性、モデル作成時間の短縮、といった利点がありますが、技術的な課題は別として様々な業界で使用するには複数の課題が残っています。
BERTの課題
ゼロからBERTを作成する際は学習コストが膨大する
BERTをファインチューニングする際は作成者が指定した最大系列長までしか指定出来ない
BERTを使用した学習、推論時間は従来技術より長い
それぞれの目的に合ったデータセット不足問題が既存モデルと同様に発生
本研究に関連する最新の研究はこちら
自然言語処理における未知語学習の効率化研究開発~学習効率を大幅に向上し特許を取得~