

講演「SCSKのLLM活用戦略 – 特化型LLM開発と展望」~HPE HPC & AI フォーラム 2024 オンライン~【後編】

2024年9月26日、「HPE HPC & AI フォーラム 2024 オンライン」が開催されました。本フォーラムに、SCSKの技術戦略本部 先進技術部 主任研究員の中本が登壇し、当社グループのLLM(大規模言語モデル)活用戦略について講演しました。
当日の講演内容から、前編ではSCSKのLLM活用方針と2023年度の取り組みについてご紹介しました。本稿では、後編として2024年度に行った追加学習・モデル生成への取り組みについてご紹介します。

中本 裕大
SCSK株式会社 技術戦略本部 先進技術部
学生時代は人工知能研究室に所属し、画像キャプション生成モデルや単語埋め込み技術の研究に取り組む。2021年にSCSKへ入社後、研究開発部署のAIチームで自然言語処理の研究開発を行う。日本語BERTモデルへの知識グラフ適用による意味理解性能向上の研究や社内向け生成AI(SCSK-GAI)の導入・開発および生成AI関連のPoCに従事。RAGの検索精度向上に向けた研究や、生成AIの業務活用にあたって利用ニーズに最適化した特化型LLMの開発に取り組んでいる。
講演「SCSKのLLM活用戦略 – 特化型LLM開発と展望」
更なる精度向上を目指した、追加学習・モデル開発への取り組み
2024年度は、さらに生成AIの活用支援を広げるべく、ステップ3以降の特化型LLMを含めた生成AI活用に取り組んでいます。SCSKではシステム開発の各フェーズにおける生成AI利用を、当社グループ全体として様々な観点で進めています。その際に、汎用LLMやRAGによる導入だけではなく、モデルのチューニング(追加学習など)を含め様々な実現方法に取り組んでいます。

LLM利用の課題
汎用LLMは1つのモデルで幅広いタスクを実行できますが、業界特有の用語や言い回しを含む質問に対して、正しい解釈を行なった上での回答ができないといった課題があります。また回答生成においては、学習時のデータに基づいた回答に限られ最新の情報を反映した回答ができない、という課題があります。
汎用LLMへの知識追加の方法の1つとして、RAGがありますが、このRAGにも課題があります。

RAGの課題に触れる前に、まずRAGの構成について説明します。RAGは概要図の通り、事前準備として、検索対象となるドキュメントを、チャンクと呼ばれる一定のサイズに分割しベクトルに変換したものをデータベースに保管します。システムの利用時に利用者が入力した質問に対して、根拠となるチャンクをデータベースから検索し、検索結果の上位数件と質問をLLMに渡すことによって回答を生成します。このアルゴリズムの特性上いくつかの課題が発生します。
RAGシステムでは複数のチャンクやドキュメント間を跨った検索に対する精度が低くなる傾向があります。これは検索対象となるドキュメントが分割されることにより、検索時に一部の情報が欠落してしまうことに起因します。RAGは利用者の質問内容に関連するドキュメントを検索し回答を行う仕組み上、RAGの仕組みをそのまま他タスク(文章解析・要約など)に適用することはできません。これらの課題を克服するため、SCSKは業界特化型モデルやユースケース別モデルの開発に取り組んでいます。具体的には、マニュアルなどの文書を基にモデルを追加学習し、専門用語や業務知識を反映できるようにしており、業務で必要とされる知識をカバーして精度の高い回答を目指しています。
特化型モデルの開発
特化型モデルでは、LLM導入対象の業務内容に関連する文書を、事前学習済モデルに追加学習させることにより、専門用語等の業務ナレッジに基づく命令内容を解釈した上で、タスクを実行させることができます。
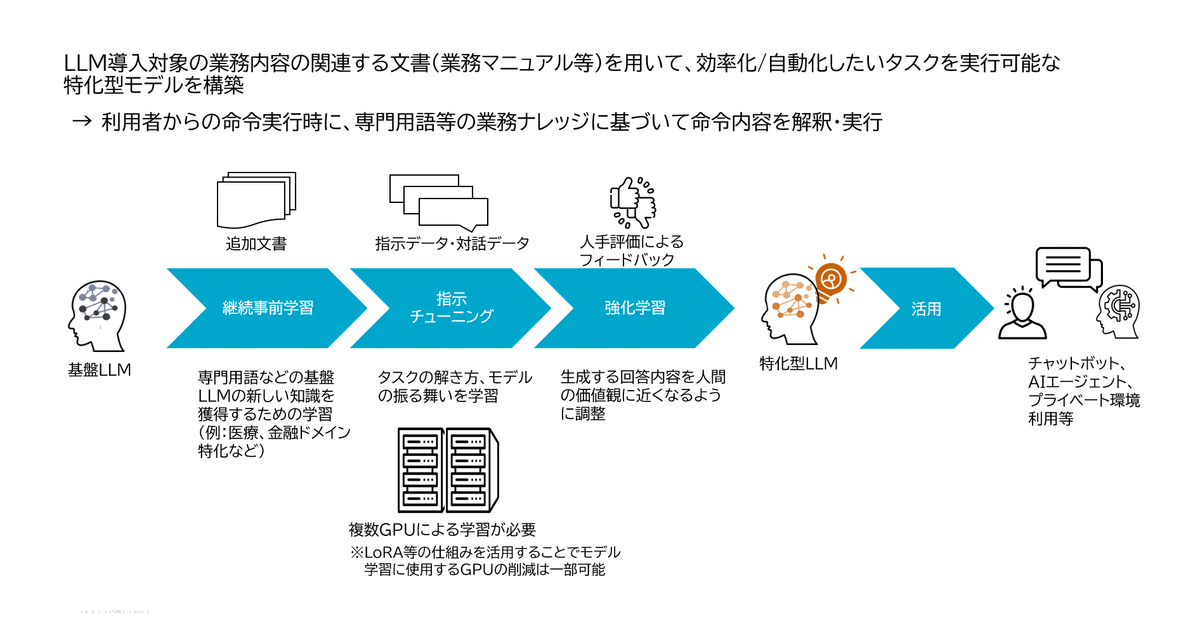
追加学習の方法は大きく3つのフェーズで実行されます。
1つ目は継続事前学習です。このフェーズでは、対象業務のドキュメントを用いてベースとするLLMに対し知識追加を目的とした学習を行います。この知識追加を行うことにより、例えば医療ドメインや金融ドメインに特化させることができます。
2つ目の指示チューニングでは、指示データや対話データを用いてタスクの解き方やモデルの振る舞いを学習させます。このステップでは、用途に合わせたタスクを定義し学習させることができます。
3つ目のフェーズでは、LLMが生成した回答に対し人によるフィードバックを行い、生成結果がより人間の価値観に近くなるよう微調整するための学習が行われます。
学習に使用するデータセット
下の画像は、継続事前学習と指示チューニングに使用するデータセットの具体例です。前述の通り継続事前学習は、会社情報や業務情報など独自ドメインの知識に対応させつつ用途別に知識を学習させる目的で実行されます。生のテキストデータをそのまま学習に使用し、テキスト上に記載された内容を繰り返し学習する中で知識を定着させていきます。

指示チューニングは、言語モデルのタスク性能改善や特定のタスクへの対応を行うことを目的としています。指示チューニングでは学習させたいタスクに合わせて、指示と応答のペアや対話データなどの模範解答例を示す教師データを用意する必要があります。この画像の例では、質問タスクに対してどのような形式で回答するかを示しています。
1つ目の例では、「健康維持のための三つのコツを教えてください。」という指示に対し、「1.バランスの取れた食事を摂る」「2.定期的に…」といった1〜3の番号付きで回答させることを学習させるデータを表しています。
2つ目の例は、「三原色とは何ですか?」という質問に対して「三原色は赤、青、黄色です。」という風に、端的に回答を生成するよう学習させるデータです。入力と出力のペアのデータを、大量に用意して学習させることにより、LLMが学習した知識をもとに指示チューニングで学習した形式での回答を可能とします。
日本語性能を持つモデルの事例と企業の特化型LLMの取り組み動向
最近はSwallow、ELYZA、Microsoft 社のPhi-3やGoogle 社のGemmaといった、小さいパラメータサイズで高い日本語性能を持つOSSのLLMも登場しました。ライセンスについても一定の条件を守れば無償で利用可能なものが多く存在します。現在、様々な企業が特定の業界や企業組織に適した言語モデルの開発と活用を進めています。これらのモデルは業界や組織に合わせたチューニングが可能です。このように、SLM(小規模言語モデル)で独自ドメインに特化したモデルを作成する方法が注目されています。
継続事前学習・指示チューニングのメモリ使用量
LLM (大規模言語モデル) の学習には膨大な計算リソースが必要です。例えば、Llama2 7Bの学習では、モデルの読み込み、順伝播、勾配計算、オプティマイザーの更新といった各ステップで大量のメモリが消費されます。学習するモデルによっては、数百GBから数TBのメモリを必要とし、1台のGPUでは処理できません。そのためGPUサーバーを利用して分散学習を行い、複数のGPUで処理を分散させることが一般的です。
特化型LLM開発環境の一例
SCSKも特化型LLM開発を進めるためにGPUサーバーを導入しています。当社で導入しているGPUサーバーは、分散学習に必要な高性能なハードウェアと優れたネットワーク帯域を備えており、80GBのNVIDIA H100のGPUを8枚搭載しています。さらに高性能なプロセッサと2048GBのメモリを搭載し、大規模データセットの処理が可能です。ネットワークに関しては、InfiniBand(※1)の高速接続がGPU間のデータを高速に転送することを可能にし、これにより分散学習効率を大幅に向上させています。
※1 InfiniBand: 非常に高いRAS(信頼性・可用性・保守性)を持つ基幹系・HPC系のサーバ/クラスター用高速入出力バスアーキテクチャ及びインターコネクト。
継続事前学習・指示チューニングの分散学習
GPUサーバーと分散学習を組み合わせることにより、どの程度メモリ消費量を分散できるかをDeepSpeed ZeRO(※2)を例に説明します。DeepSpeed ZeROには、ステージ1~3の段階があり、どの程度モデルを分割するかに対応しています。SCSKが導入したGPUサーバーに合わせて8個のGPUサーバーで学習を分割した場合の結果は下記のとおりです。
ZeRO-1: オプティマイザーの状態をGPU間で分割し、メモリ消費を63GB+フォワードメモリまで削減
ZeRO-2: オプティマイザーの状態に加えて勾配情報も分割し、38.5GB+フォワードメモリまで削減
このように分散学習を使用することで、効率的なLLM学習が可能です。
※2 DeepSpeed ZeRO: DeepSpeedは、深層学習において自然言語モデルのトレーニング効率化を向上させる技術。並列化オプティマイザーZeROを搭載し、データの並列化に要するリソースを節約できる。

SCSKにおける特化型LLMの取り組み内容
SCSKでの特化型LLMの取り組み内容の一つを紹介します。当社では日本の法律データを使用して知識追加を目的とした学習を行い、追加した知識に基づく質疑応答が可能であるか技術検証を行いました。本取り組みでは、Swallow-13b-hfモデルを使用し、学習にはH100のGPUを4枚使用しました。
学習モデルは2つの観点から評価を行いました。1つ目は既存の日本語性能が維持されているかを確認するもので、追加学習後にベースとしたLLMの日本語性能が改悪されていないかを確認します。評価には複数のベンチマークデータセットを使用しています。
2つ目は追加知識に対する回答精度評価で、学習した法律データからQAデータセットを作成し、質問に対して生成した回答と模範解答との比較をLLMの自動評価によって行います。ここで使用するLLMには、例えばGPT-4oなどがあります。
MLDEを使用したパラメータ探索
当社ではモデル学習を効率的に実施するために、HP社のMachine Learning Development Environment (MLDE)(※3)を導入しています。MLDEで複数のGPUリソース管理を行い、効率的にモデル学習を実行しています。LLMの学習で重要となるパラメータ調整についても、MLDEの機能を使用することで学習に使用するデータやモデルサイズに合わせて最適なパラメータ探索の自動化を行っています。
※3 MLDE: HP社の提供する機械学習のための開発環境。GPUリソース管理や自動ハイパーパラメーターチューニング、チェックポイント機能などを提供し、機械学習の効率的な開発と運用を支援する。

今後の展望
SCSKは前述のGPUサーバーを最大限活用し、引き続きLLMのファインチューニングによる特定ニーズに応じた個別LLMの開発を目指します。また、リソースを節約しつつ特定のタスクに最適化されたSLMの構築にも取り組んでまいります。
先進デジタル技術の最大活用による事業構造の変革や生成AI活用による飛躍的な生産性向上の実現を目指す、SCSK技術戦略「技術ビジョン2030」を公開しました。詳細は、下記リンクからご覧いただけます。
https://www.scsk.jp/sp/technology_strategy/index.html
また、SCSKでは共に活躍していただける高度デジタル人材を募集しています。詳細は各採用サイトをご覧ください。
新卒採用サイト
https://www.scsk.jp/recruit/saiyo/
キャリア採用サイト
https://www.scsk.jp/recruit/career/